Estimación
Métodos y Simulación Estadística
Propiedad de los estimadores
El siguiente problema tiene como objetivo visualizar las principales propiedades de los estimadores : insesgadez, eficiencia y suficiencia. Con este propósito se realizará la simulación de una muestra aleatoria proveniente de una distribución uniforme.
Problema :
Para una variable con distribución uniforme \(X \sim unif(x,a=0, b=20)\) se desea determinar las propiedades de los siguientes estimadores del parámetro \(b\)
\(\widehat{\theta_{1}} = 2 \bar{x}\)
\(\widehat{\theta_{2}} = \max\{x\}\)
\(\widehat{\theta_{3}} = \dfrac{(n+1)}{n} \max\{x\}\)
# uniforme
library(ggplot2)
x= c(0,20)
fx=c(1/20, 1/20)
dat=data.frame(x,fx)
ggplot(data=dat,aes(x=x, y=fx))+
scale_y_continuous(limits=c(0,.05))+
geom_line(size = 1,colour = "#FF7F00") 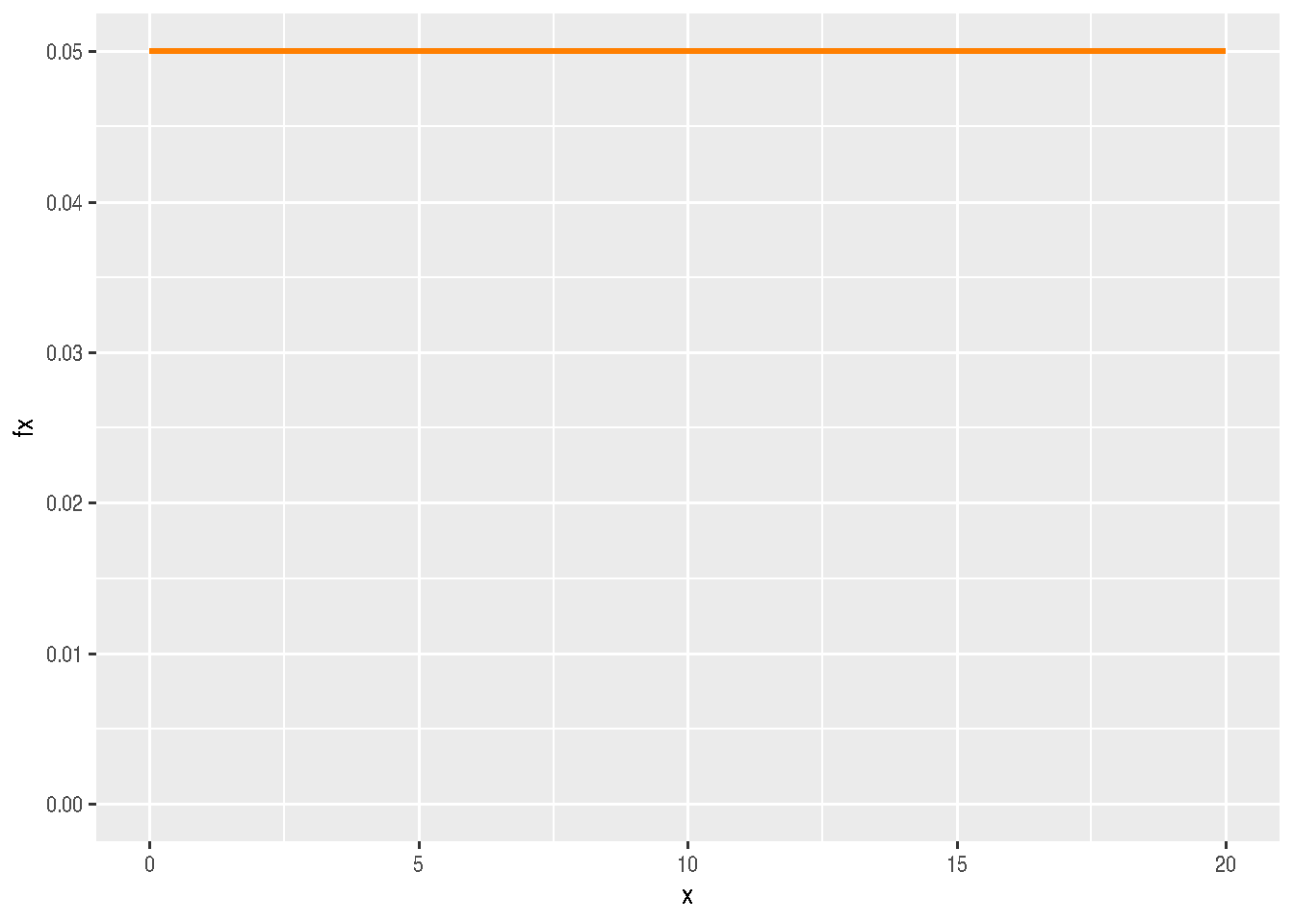
Para ello se realiza una simulación, para posteriormente evaluar los estimadores propuestos y determinar sus propiedades.
library(ggplot2)
n=10 # n: tamaño de muestra
m=1000*n # m tamaño de replicas del experimento
Y=matrix(runif(m, min=0, max=20), ncol=n) # Matriz de datos m x n
Mx=apply(Y,1,mean) # Cálculo de la media para las m muestra
Max=apply(Y,1,max) # Cálculo del valor máximo para las m muestras
T1=2*Mx # Cálculo de los m valores para el estimador 1
T2=Max # Cálculo de los m valores para el estimador 2
T3=((n+1)/n)*T2 # Cálculo de los m valores para el estimador 3
T123=data.frame(T1,T2,T3) # data.frame con los tres estimadores data de m x 3
boxplot(T123, las=1, main="Comparación estimadores con n=10") # Gráfico de comparación
abline(h=20, col="red") # Línea indicando el parámetro b=20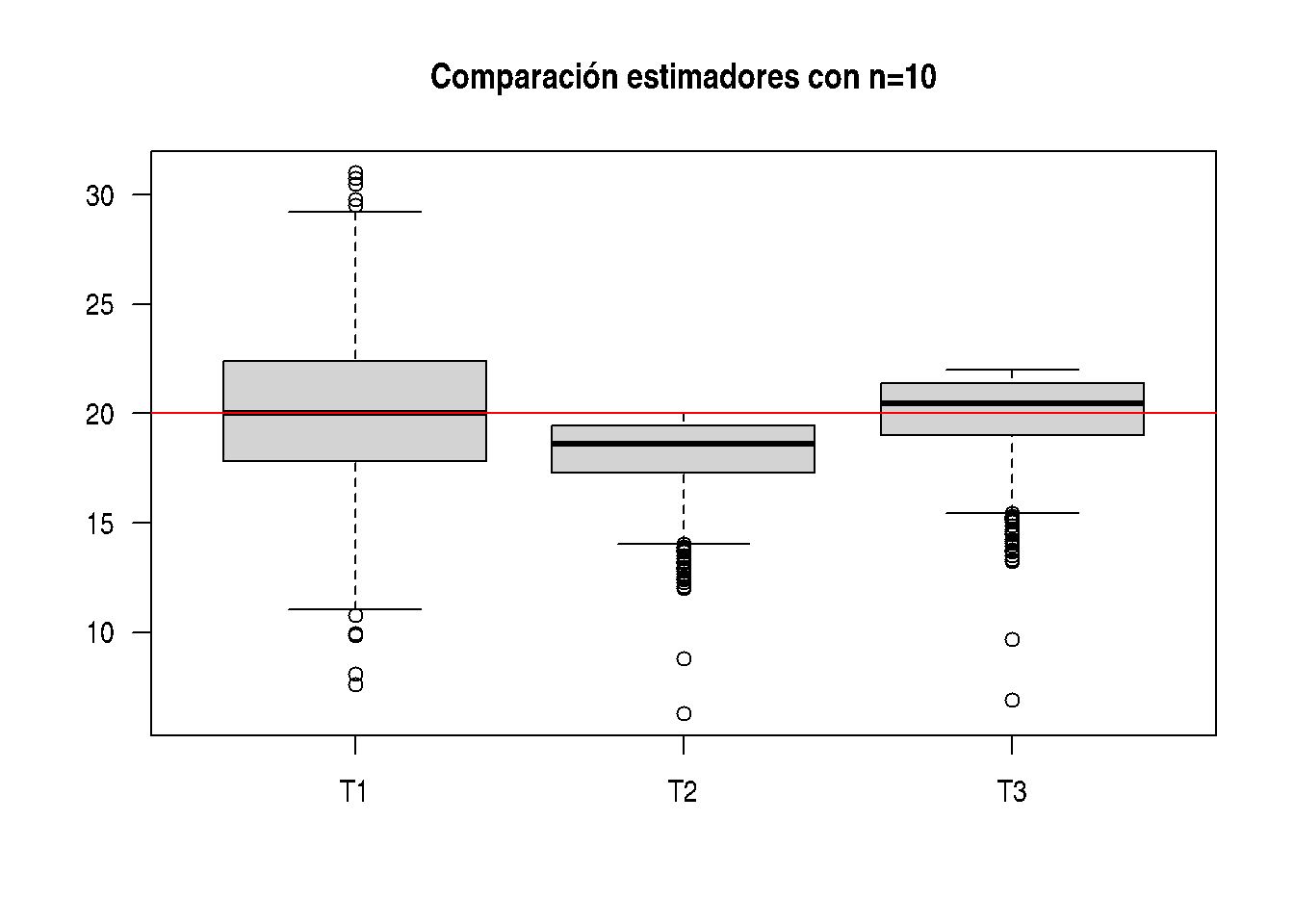
apply(T123,2,mean) # Valores de las medias T1 T2 T3
20.15104 18.13786 19.95164 apply(T123,2,sd) # Valores de la desviaciones estándar T1 T2 T3
3.581697 1.692030 1.861233 Para un tamaño de muestra n=10 se observa que los mejores resultados se obtienen con T3. Este estimador se puede clasificar como INSESGADO y EFICIENTE, pues ademas que su promedio está muy cerca de 20, tiene la menor varianza
n=100
m=1000*n
Y=matrix(runif(m, min=0, max=20), ncol=n)
Mx=apply(Y,1,mean)
Max=apply(Y,1,max)
T1=2*Mx
T2=Max
T3=((n+1)/n)*T2
T123=data.frame(T1,T2,T3)
boxplot(T123, las=1, main="Comparación estimadores con n=100")
abline(h=20, col="red")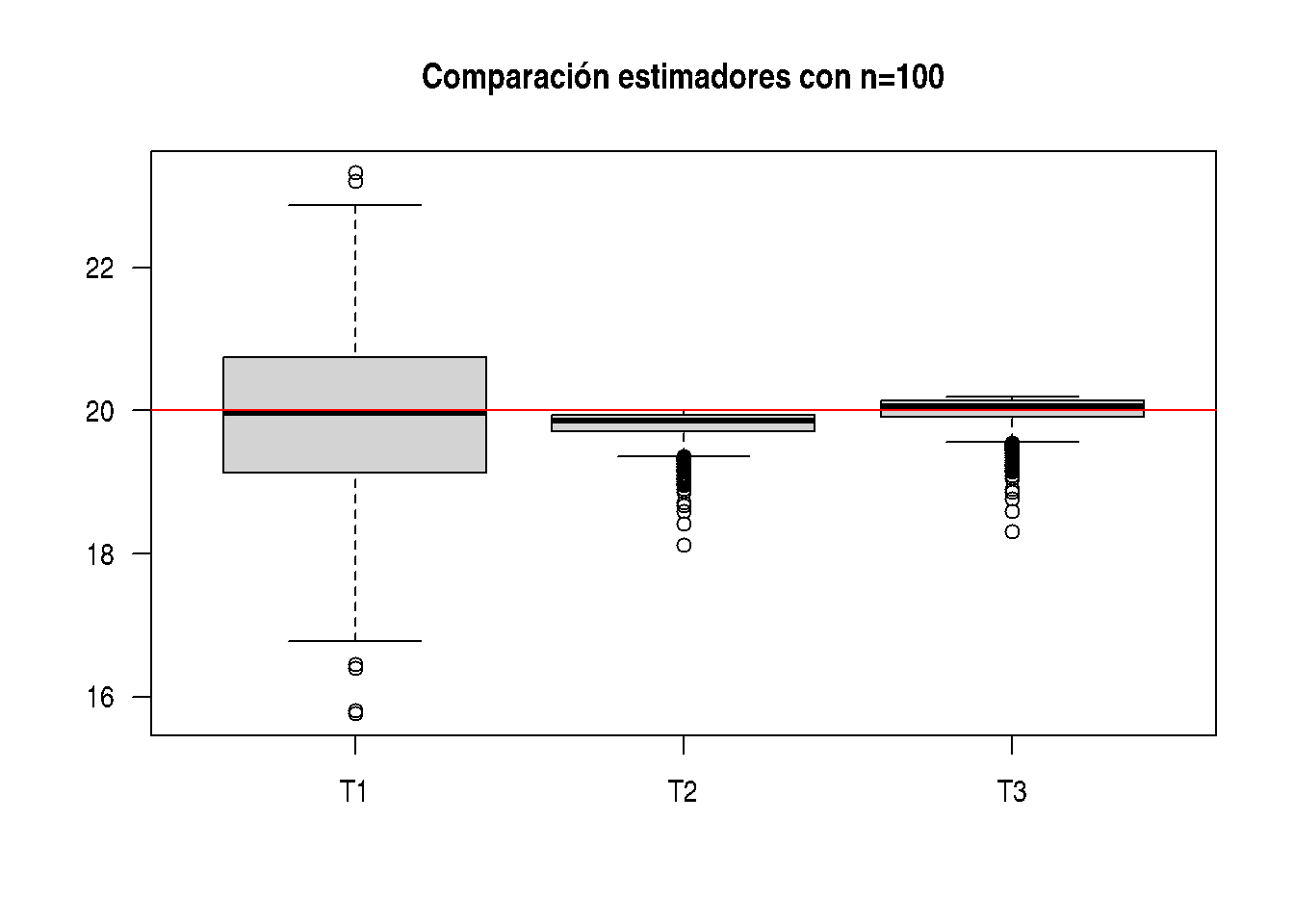
apply(T123,2,mean) T1 T2 T3
19.94354 19.79453 19.99248 apply(T123,2,sd) T1 T2 T3
1.1829769 0.2137587 0.2158963 Los resultados indican que el mejor estimador de b corresponde a T3. Sin embargo el estimador T2 que era insesgado al aumentar el tamaño de la muestra pasando de n=10 a n=100 se observa que su promedio se acerca mas a 20 que corresponde al valor del parámetro
Teorema del Límite Central
El Teorema del Límite Central (TLC) es un concepto fundamental en la teoría de probabilidad y estadística. Describe el comportamiento de las sumas o promedios de un gran número de variables aleatorias independientes e idénticamente distribuidas (IID) cuando el número de variables aumenta. En otras palabras, el teorema establece que, bajo ciertas condiciones, la distribución de la suma o el promedio de muchas variables aleatorias tiende a aproximarse a una distribución normal, independientemente de la distribución original de las variables.
El Teorema del Límite Central es importante porque permite inferir propiedades sobre la distribución de una muestra, incluso si la distribución original de los datos no es normal. Esto es especialmente relevante en la estadística, ya que muchos métodos y pruebas estadísticas asumen una distribución normal para funcionar de manera efectiva. El TLC ofrece una justificación teórica para esta suposición en situaciones en las que se cumplan las condiciones necesarias.
Las condiciones para que el Teorema del Límite Central se aplique incluyen:
- Independencia: Las variables aleatorias deben ser independientes entre sí.
- Identidad: Las variables aleatorias deben tener la misma distribución.
- Tamaño de muestra suficientemente grande: A medida que el tamaño de la muestra aumenta, la aproximación a la distribución normal mejora.
Verificación del Teorema del Límite Central para una población exponencial con \(\lambda=1\)
Con este fin se siguen los siguientes pasos:
- Se construye una matriz de dimensión \(1000\) x \(1000\) con números procedentes del modelo determinado
- Se separan matrices de dimensión \(1000\) x \(n\) , para \(n=1,2,20,30,50,100\) y \(1000\).
- A cada matriz construida en el paso anterior se le calcula la media por filas, como resultado se obtiene un vector de \(1000\) medias
- Cada uno de los vectores resultantes se visualiza a través de un histograma, gráfico de densidad y se construye también un gráfico de normalidad con el fin de validar el resultado
par(cex=0.5, cex.axis=.5, cex.lab=.5, cex.main=.5, cex.sub=.5, mfrow=c(3,2), mai = c(.5, .5, .5, .5))
# Teorema Central del Límite-----------------------------
# Paso 1
n=1000 # Numero de columnas (tamaño máximo de muestra)
m=1000*n
# Caso --------------------------------------------------
# Distribución exponencial-------------------------------
X=matrix(rexp(m,1),ncol=n) #############################
# Paso 2
# Generación de muestras--------------------------------
X1=X[ ,1] # n=1
X2=X[ ,1:2] # n=2
X20=X[ ,1:20] # n=20
X30=X[ ,1:30] # n=30
X50=X[ ,1:50] # n=50
X100=X[ ,1:100] # n=100
X1000=X[ ,1:1000] # n=1000
# Paso 3
# Generación de medias-------------------------------------------
Mx2=apply(X2,1,mean) # medias de muestras de tamaño n=2
Mx20=apply(X20,1,mean) # medias de muestras de tamaño n=20
Mx30=apply(X30,1,mean) # medias de muestras de tamaño n=30
Mx50=apply(X50,1,mean) # medias de muestras de tamaño n=50
Mx100=apply(X100,1,mean) # medias de muestras de tamaño n=100
Mx1000=apply(X1000,1,mean) # medias de muestras de tamaño n=1000
# Paso 4
# Generación de densidad empírica -------------------------------
d=density(X1)
d2=density(Mx2)
#d20=density(Mx20)
d30=density(Mx30)
d50=density(Mx50)
d100=density(Mx100)
d1000=density(Mx1000)
# Gráficos de densidad -------------------------------------------
# Configuración de las gráficas
par(cex=0.5, cex.axis=.5, cex.lab=.5, cex.main=.5, cex.sub=.5, mfrow=c(2,3), mai = c(.5, .5, .5, .5))
# Histogramas de comparación-------------------------------------
plot(d, main=" ", xlab = "n=1")
plot(d2,main=" ", xlab = "n=2")
#plot(d20, main="", xlab = "n=20")
plot(d30, main=" ", xlab = "n=30")
plot(d50, main=" ", xlab = "n=50")
plot(d100, main=" ", xlab = "n=100")
plot(d1000,main=" ", xlab="n=1000")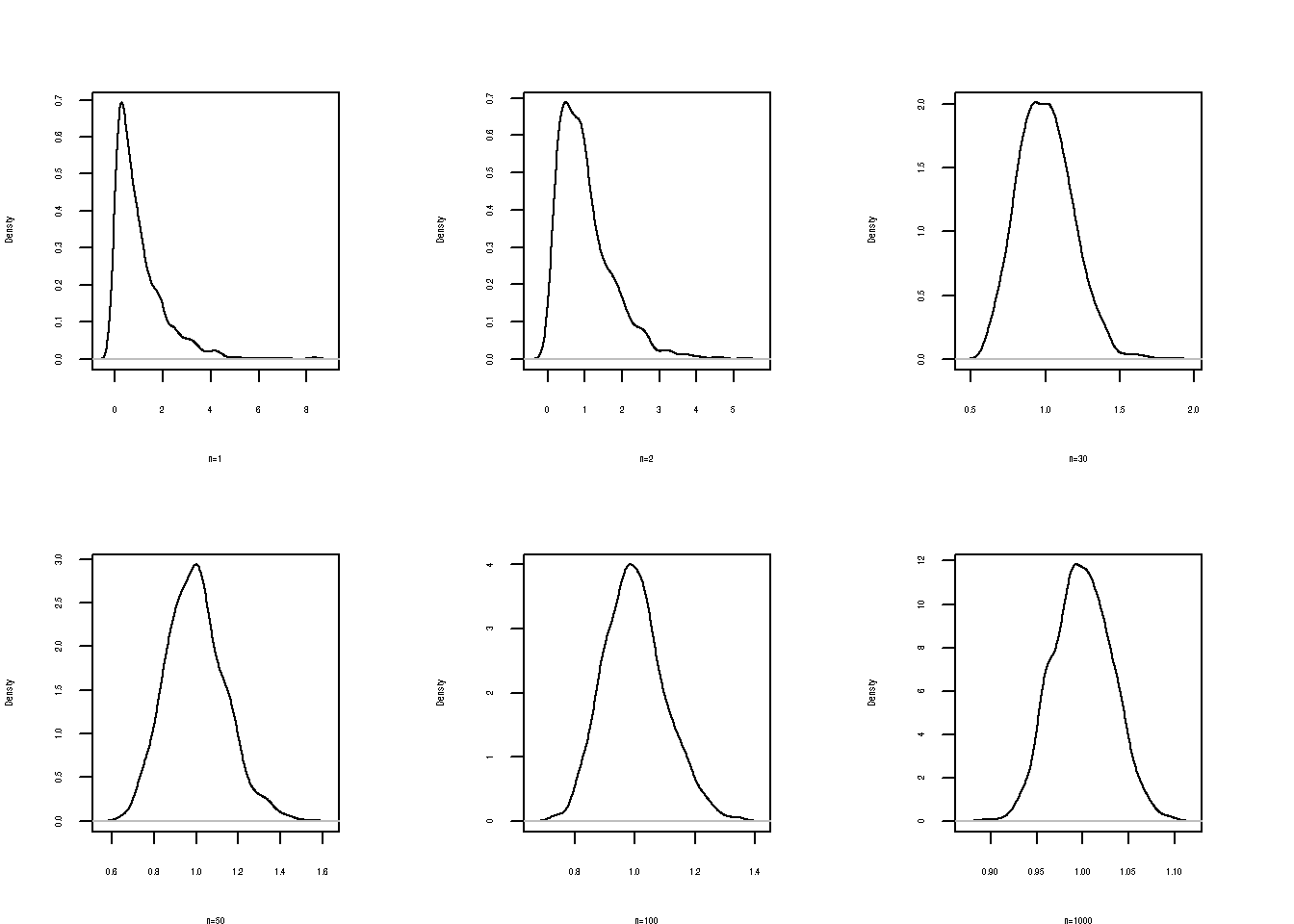
# Histogramas de comparación-------------------------------------
hist(X1, main = "n=1", freq=FALSE)
hist(Mx2, main ="n=2", freq=FALSE)
# hist(Mx20, main = "n=20",freq=FALSE)
hist(Mx30, main = "n=30",freq=FALSE)
hist(Mx50, main = "n=50",freq=FALSE)
hist(Mx100, main = "n=100", freq=FALSE)
hist(Mx1000, main = "n=1000", freq = FALSE) 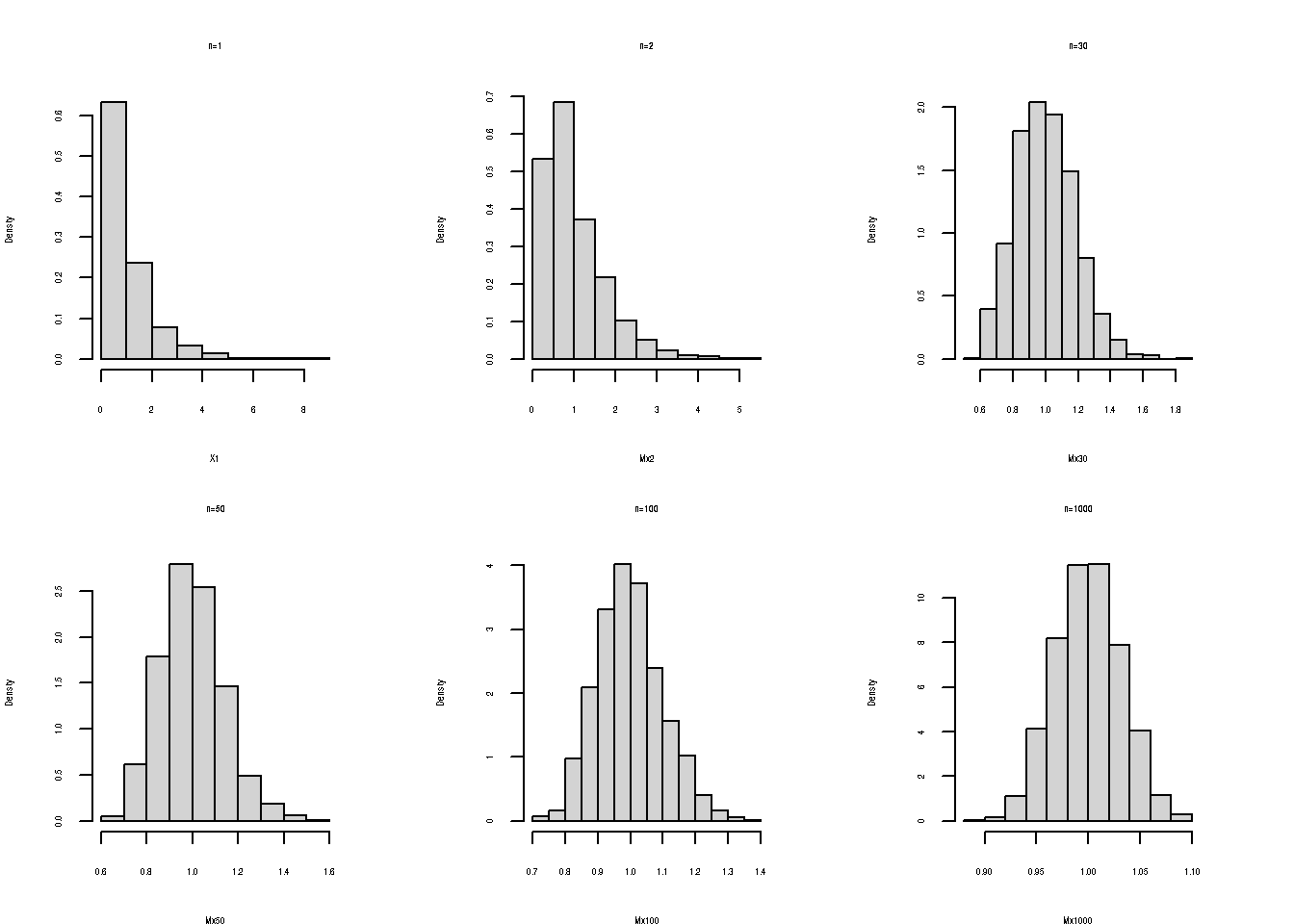
# Histogramas de comparación--------------------------
qqnorm(X1) ; qqline(X1, col="red")
qqnorm(Mx2) ; qqline(Mx2, col="red")
# qqnorm(Mx20) ; qqline(Mx20, col="red")
qqnorm(Mx30) ; qqline(Mx30, col="red")
qqnorm(Mx50) ; qqline(Mx50, col="red")
qqnorm(Mx100) ; qqline(Mx100, col="red")
qqnorm(Mx1000) ; qqline(Mx1000, col="red")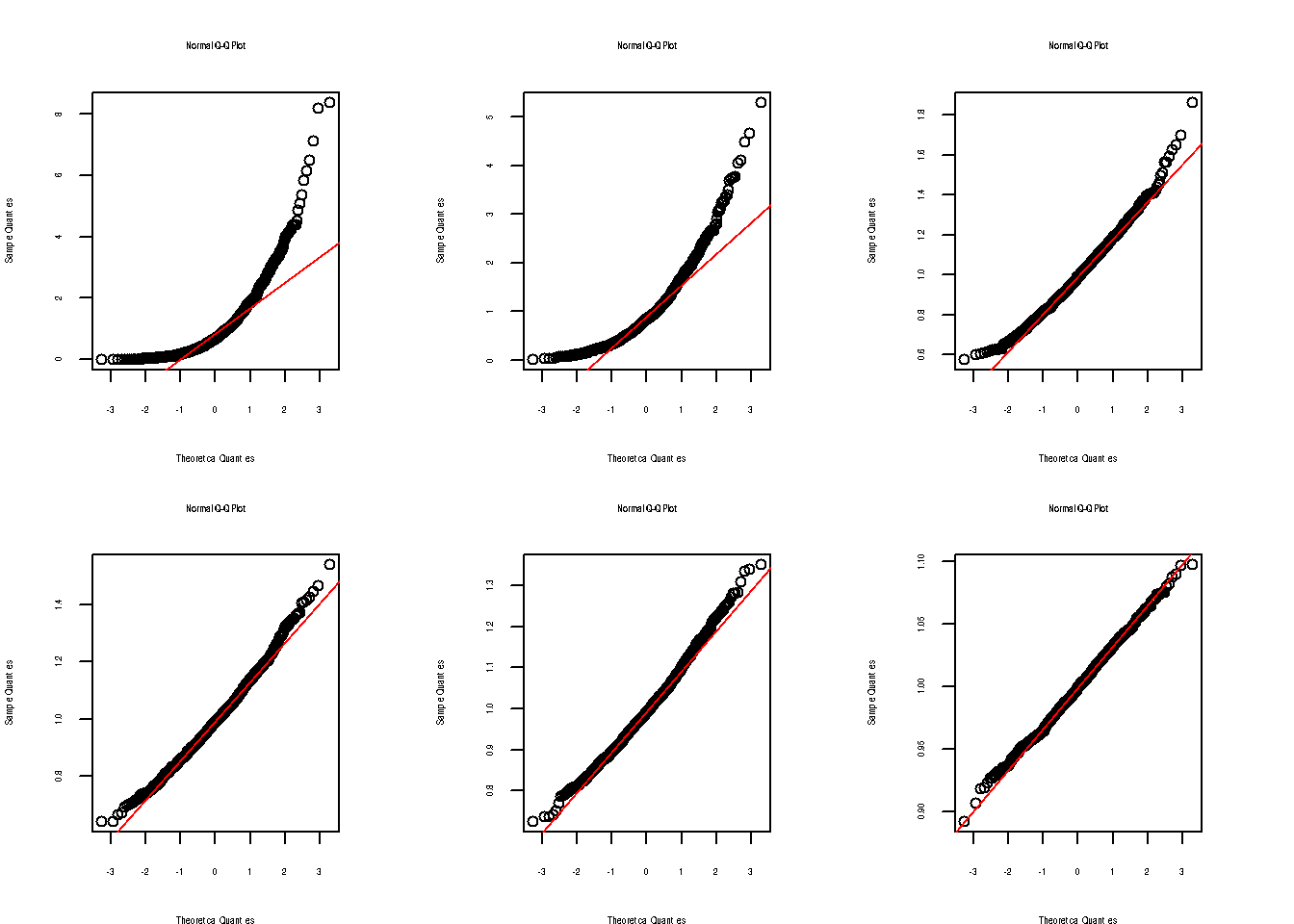
Se puede observar la convergencia de la distribución de la media muestral a una distribución normal al aumentarse el tamaño de la muestra